空间智能:实现通用具身大脑的基石
发布时间:2025-04-09 14:58:53 | 来源:中国网 | 作者: | 责任编辑:吴一凡随着多模态大模型的快速发展与成熟,其在实现通用具身智能这一目标中的重要性日益凸显。然而经典多模态大模型主要关注二维视觉与语言,其三维空间感知能力弱。空间智能(Spatial Intelligence),一个专注于模型对三维世界理解能力的研究方向时下逐渐兴起。近日,上海交通大学人工智能学院赵波副教授团队,联合斯坦福大学、牛津大学、北京大学、智源研究院等,在空间智能领域做出了多项有影响力的技术突破。
尽管大模型已经在语义方面被广泛且深入地评测,其时空感知能力仍缺乏有效的评测基准,尤其是精确定量的评估。赵波团队针对这一问题提出了首个大模型时空智能(Spatial-Temporal Intelligence)定量评估基准 STI-Bench。在桌面、室内、室外三个场景中,设计了8个类型的任务,全面地评估大模型在三维空间度量、细粒度视觉语义对齐、运动轨迹推理、速度和加速度估计等方面的能力。这一评测基准将会为具身智能和自动驾驶等领域提供可靠的模型设计参考。通过对主流的闭源模型如 GPT-4o、Gemini和开源模型如Qwen、Intern-VL等的评测,团队发现当前多模态大模型在精准定量时空感知理解方面能力仍然较弱,因此难以为下游任务提供精准的感知和推理结果。团队提出的评测基准为未来多模态大模型的发展方向提供了重要的指引。
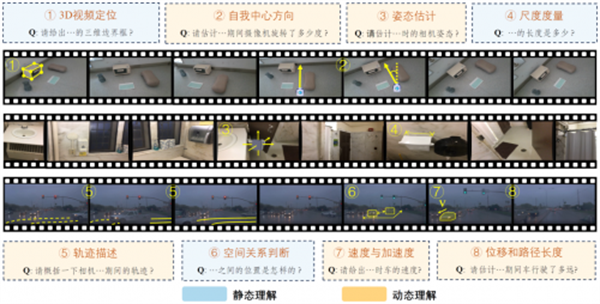
图1:大模型时空智能评测基准 STI-Bench
团队针对多模态大模型空间感知能力弱的问题,提出了一种基于 RGB+D (彩色图+深度图)输入的空间感知大模型SpatialBot。该大模型首先基于用户问题和RGB-D图片信息,生成 API调用指令,用于提取关键人物/物体/场景的深度信息。随后,将提取的深度信息与用户输入再次输入大模型,使得模型基于前一轮语义和空间信息做出新一轮推理并回答用户的问题。团队构造并开源了大规模的空间感知训练数据集 SpatialQA,该数据集包含多模态大模型多层次的空间感知训练数据,并特别设计了机器人物体抓取任务中的空间理解数据。基于此,团队训练出 SpatialBot等模型,并在空间场景理解、物体抓取、视觉自主导航等具身相关任务中取得了领先的性能。该工作已在机器人领域重要学术会议 ICRA 2025上发表,并已被李飞飞教授等国内外知名团队论文引用。
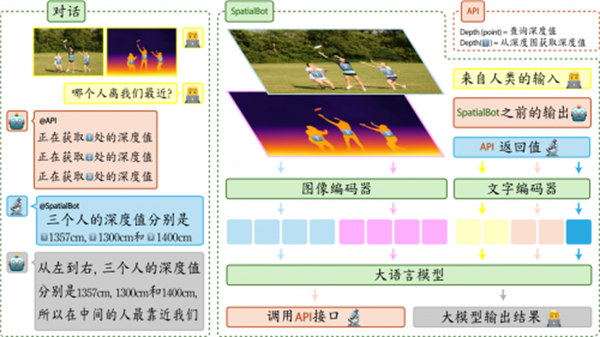
图2:空间理解大模型 SpatialBot架构与推理方式
精准的三维空间感知能力被确认后,团队将关注点瞄准大模型对时间这一重要概念的感知能力,研究如何用大模型进行长视频理解。长视频理解对于自动驾驶、具身智能、智能安防、视频教学、影视广告等任务有重要意义。团队首先提出了长视频理解评测集 MLVU,包含平均超过15分钟、最大2个多小时的、丰富类型的视频数据。从视频情节推理、动作识别排序、异常检测等九种任务全方面评测大模型能力。团队研究认为当前基于大模型的长视频理解任务最核心的挑战在于如何高效且高保真地对长视频进行信息压缩和提取。为了解决这一问题,团队提出小时级长视频理解模型 Video-XL,这一成果发表于 CVPR 2025 Oral,该研究借助大模型自身的信息压缩能力,以实现视觉 Token的自适应压缩。近期团队又推出了增强版模型 Video-XL-Pro,更系统地从空间和时间两个维度对视觉 Token进一步压缩。实现了以 3B参数轻量级大模型达到世界领先水平,超越 Meta公司 7B参数模型的效果。团队致力于推动基于空间智能的通用具身大脑研究和落地,相关研究成果对促进具身智能中的长程任务执行和物理世界理解具有重要意义。(周芳)