阿里首次公布自然语言处理成果
发布时间:2017-07-20 16:25:17 | 来源:机器之心 | 作者:佚名 | 责任编辑:胡俊业界普遍认为,自然语言处理是人工智能中最难的部分,也是决定 AI 是否「智能」的关键因素。王成龙在接受机器之心采访时说,「阿里巴巴在语音交互技术方面已经深耕多年,并已在多类产品中应用。
针对这篇论文,该团队向机器之心发布了独家技术解读:
语义编码的意义
自然语言这一被人类发明的信号系统,通常被我们归为一种「非结构化数据」。其原因在于,自然语言文本是由一堆符号(token)顺序拼接而成的不定长序列,很难直接转变为计算机所能理解的数值型数据,因而无法直接进行进一步的计算处理。语义编码的目标即在于如何对这种符号序列进行数值化编码,以便于进一步地提取和应用其中所蕴含的丰富信息。语义编码是所有自然语言处理(Natural Language Processing,NLP)工作的「第一步「,同时也很大程度地决定了后续应用的效果。
传统的文本编码方式通常将其当作离散型数据,即将每个单词(符号)作为一个独立的离散型数值,如 Bag-of-Words (BOW)、TF-IDF 等。但是这类方法忽略了单词与单词之间的语义关联性,同时也难以对单词的顺序及上下文依赖信息进行有效编码。近几年,深度学习技术被广泛的应用于 NLP 领域,并在众多算法命题上取得了突破。其本质在于,深度神经网络在特征提取(语义编码)上具有极大的优势。
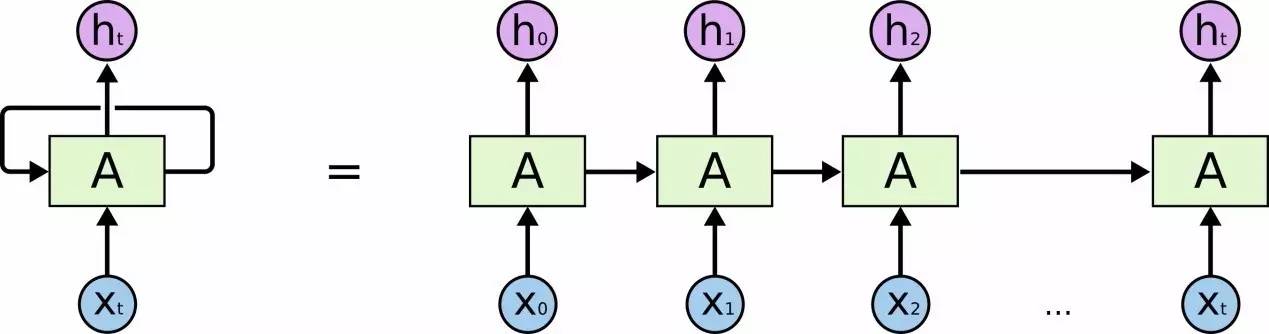
已有方法的瓶颈
当前,较为常用的文本语义编码模型包括循环神经网络(Recurrent Neural Network,RNN)以及卷积神经网络(Convolution Neural Network,CNN)。